
“看见”的能力始终伴随着“不看见”的能力,正如“太极”的两部分。什么是看见?看见一片大海、一片星空、一片沙漠,是看见吗?正是由于有选择的不看见的能力,忽略过滤排除筛选,去除大量无效信息,才能拨云见日、从茫茫大海星空沙漠中看见更加有价值的东西。
本文由我在互联网安全大会 ISC 2022 分论坛“以对手为目标的威胁防御——安全情报与高级威胁论坛”中的分享《基于海量样本数据的高级威胁发现》整理而成,内容有所改动。这次分享主要从 4 个方面呈现,分别是:严峻的网络威胁形势、恶意行为自动化检测技术、海量样本数据运营、情报生产和高级威胁发现。

严峻的网络威胁形势
随着互联网和信息技术的高速发展,各行各业各领域都在加快实现信息化升级,互联网技术与大众生活产生越来越密切的联系,但与此同时,网络攻击的数量和影响在过去十几年中急剧增加,网络威胁的阴霾始终笼罩在网络空间的上空。
2022 年 5 月互联网网络安全状况主要数据
CNCERT 在今年五月总第 137 期的《互联网安全威胁报告》中指出:
- 境内感染木马或僵尸网络恶意程序的受控主机 IP 地址数量约为 478 万个
- 境内被篡改网站数量为 5279 个;境内被植入后门网站数量为 1838 个;针对境内网站的仿冒页面数量为 16540 个
- 国家信息安全漏洞共享平台(CNVD)收集整理信息系统安全漏洞 1548 个,其中高危漏洞 546 个,可被利用来实施远程攻击的漏洞有 1274 个
这些数据体现出的是,我们目前网络空间面临的威胁还持续处在一个比较严峻的形势。
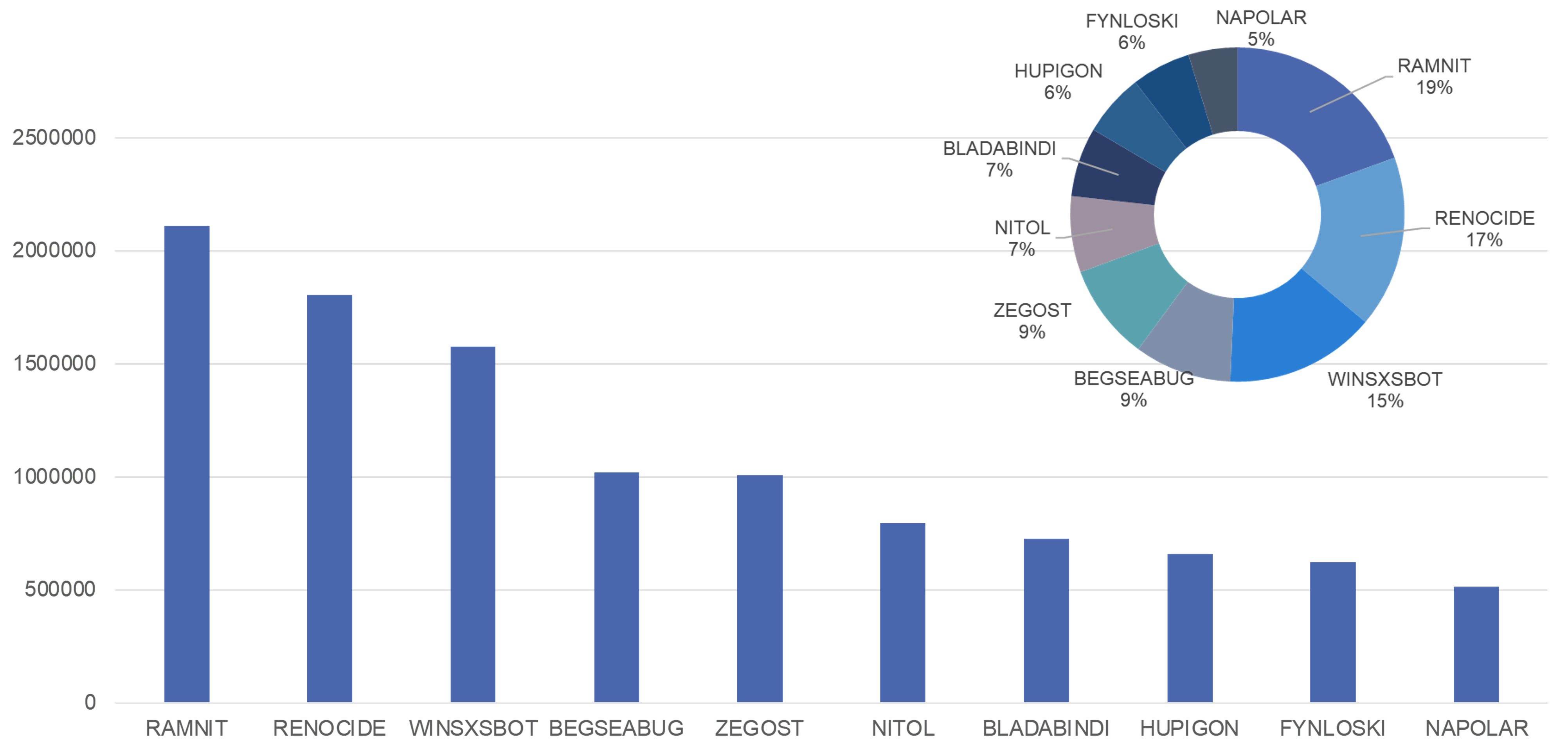
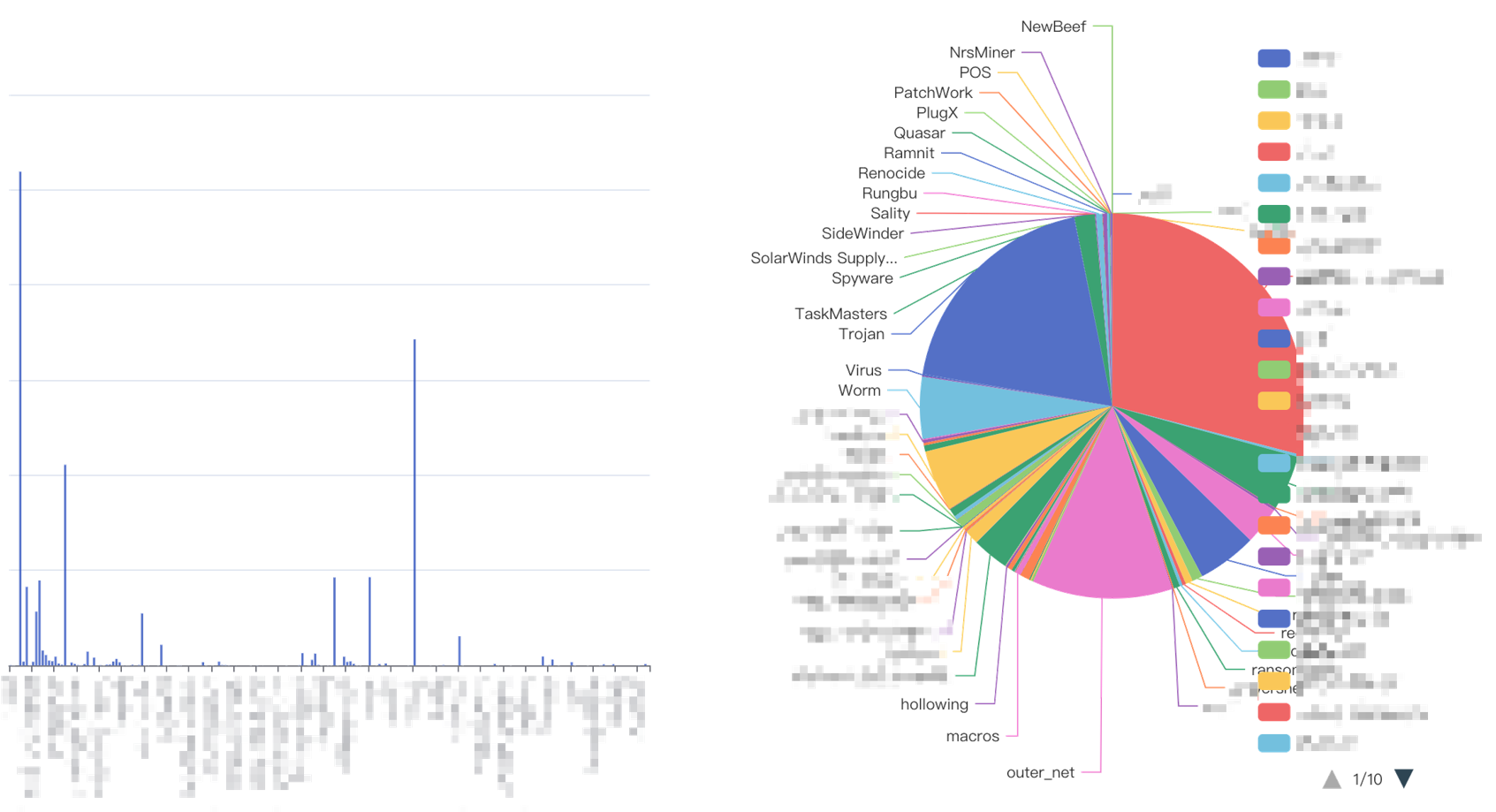
沙箱云监测恶意软件家族
我们通过沙箱云等监测系统,持续关注互联网中的恶意软件的活跃动态。下图是我们通过沙箱云在一段时间内监测到的恶意软件样本的数量和各恶意软件家族占比的情况。数据来源是用户在沙箱云提交监测的样本,还有我们内部通过样本运营流程检测的数据,大致反映了目前我们已知特征的恶意软件家族的活跃情况。
沙箱云监测漏洞利用样本
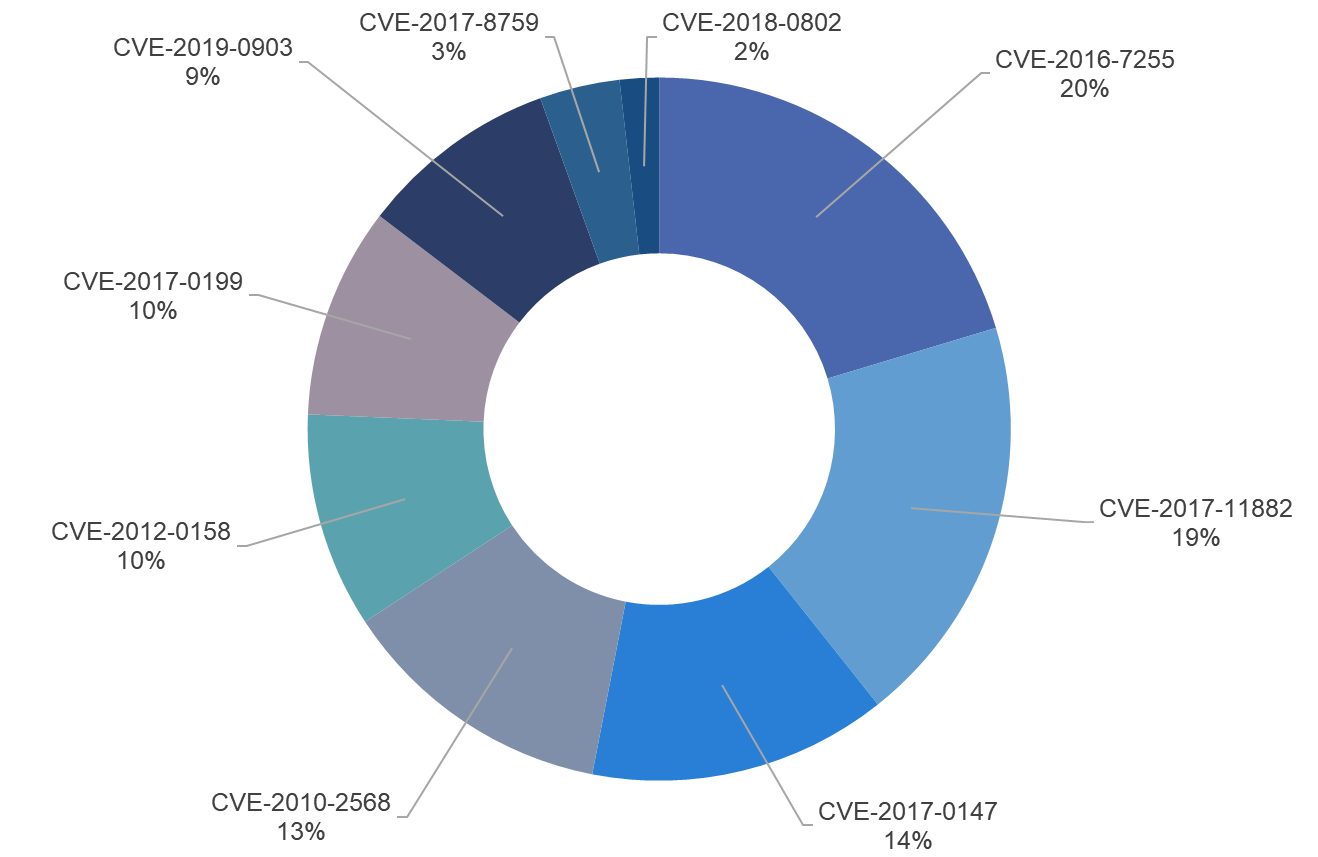
除了恶意软件家族之外,我们通过沙箱云还在持续监测互联网中的 N-day 漏洞利用的活跃情况。这些 N-day 漏洞覆盖了操作系统和流行应用软件。从理论上讲,在厂商公布修复补丁之后,漏洞将不再具有广泛的危害性;但是实际上,由于各种各样的原因,很多用户、甚至大中小企业,并没有完成漏洞修复的工作。有些是由于重视程度的原因,有些是业务环境条件不允许,有些则甚至不知道有软件漏洞这回事,但是无论是什么样的原因,导致的结果就是他们将始终暴漏在遭受这些已知漏洞攻击的风险当中,这给了越来越多的 N-day 漏洞持续滋生的条件。
延续多年的两国纷争:现实世界中的 APT 攻击
俄罗斯和乌克兰之间的特别军事行动从今年 3 月持续至今,引起了全世界各界的广泛关注。其实早在 2018 年,我们通过沙箱云就曾捕获到一例乌克兰针对俄罗斯的使用了在野 0day 漏洞的 APT 攻击样本。我们在第一时间将漏洞细节提交给厂商,协助厂商对此漏洞进行修复,并获得 CVE-2018-15982 的漏洞编号。
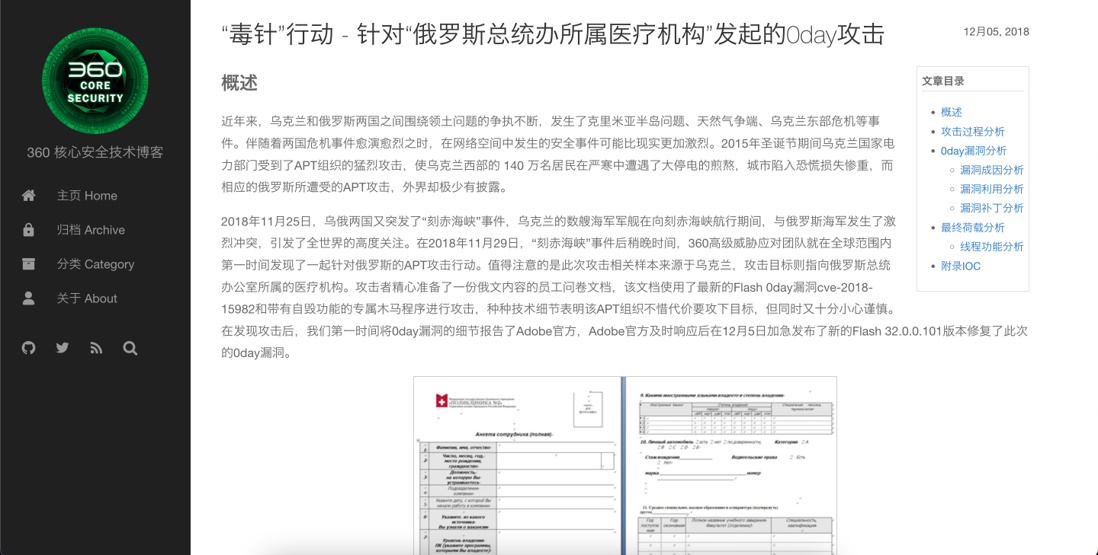
此次攻击的目标是俄罗斯总统办公室下属的医疗机构。攻击者精心伪造了面向俄语员工的调查问卷文档,在文档文件中内嵌了利用此 0day 漏洞的 Flash 对象,并捆绑了带有自毁功能的专属木马程序实施载荷阶段的攻击活动。这起攻击事件最终被命名为“毒针”行动。
恶意行为自动化检测技术
为了应对这些越来越多愈演愈烈的网络威胁,必须及时获取有关这些威胁的准确信息以进行应对。如何有效获取、收集和处理这些信息正在成为威胁应对过程中的主要挑战。这首先需要一种针对恶意行为的自动化检测技术。
沙箱
我们使用沙箱技术来应对恶意行为的自动化检测。
什么是沙箱?首先是提供一个相互隔离的虚拟化运行环境,在这个虚拟化运行环境里可以运行目标样本,包括文件或 URL;然后在样本运行的过程中,可以实时监控并记录目标样本产生的行为,并根据记录的行为分析并判定样本的风险指数,得出评估结论:恶意、可疑或是正常的;与此同时,面向专业分析人员提供得出此评估结论的详细分析依据。

基于沙箱的行为检测
基于沙箱的行为检测意思是在样本运行的过程中记录样本产生的行为和痕迹,包括调用了什么系统 API、创建或操作了什么进程、释放了什么文件、注入了什么内存,产生了哪些网络连接和通信、利用了哪些漏洞、并且用的哪些利用方式,等等。另外在样本运行过程中,通过用户模拟技术,与需要用户响应的窗口和控件进行交互,以使一些阻塞或等待的情况能够继续向后执行。在样本运行过程中,录制的屏幕图像也可以作为威胁分析过程中的重要参考。
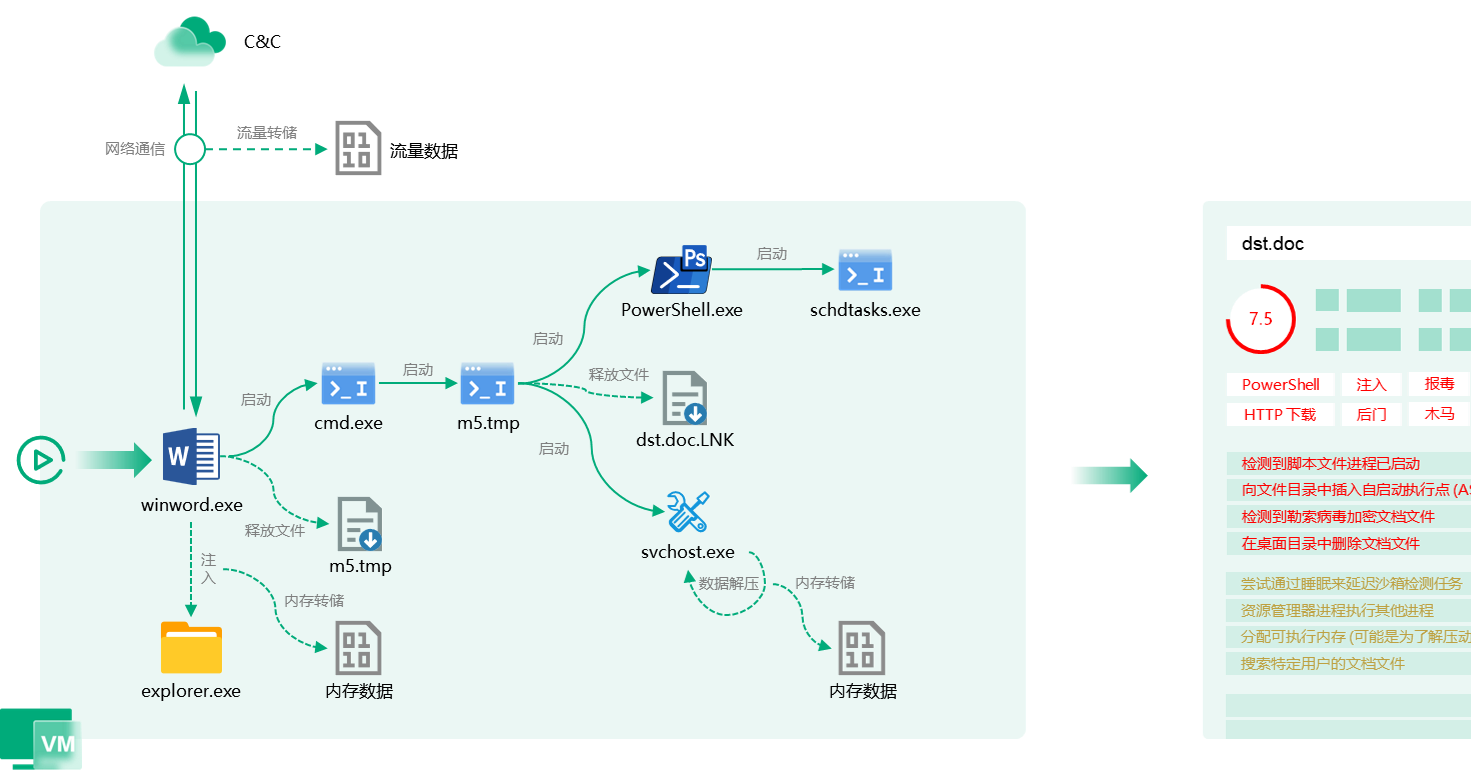
基于沙箱的漏洞利用检测
现代网络战争,漏洞先行。
在 MITRE ATT&CK™ 攻击矩阵模型中,除去侦察和资源开发两个前置战术阶段之外,从初始访问开始,共有 6 个战术阶段中存在与漏洞利用有关的技术点。作为高级威胁攻击的核心,漏洞利用的手段已经覆盖到现代网络战争的方方面面。因此,对应的漏洞利用检测技术在自动化检测过程中就处于非常重要的位置。在这里,我将以内核提权漏洞利用为例简单描述一下漏洞利用的过程和对应的检测思路。
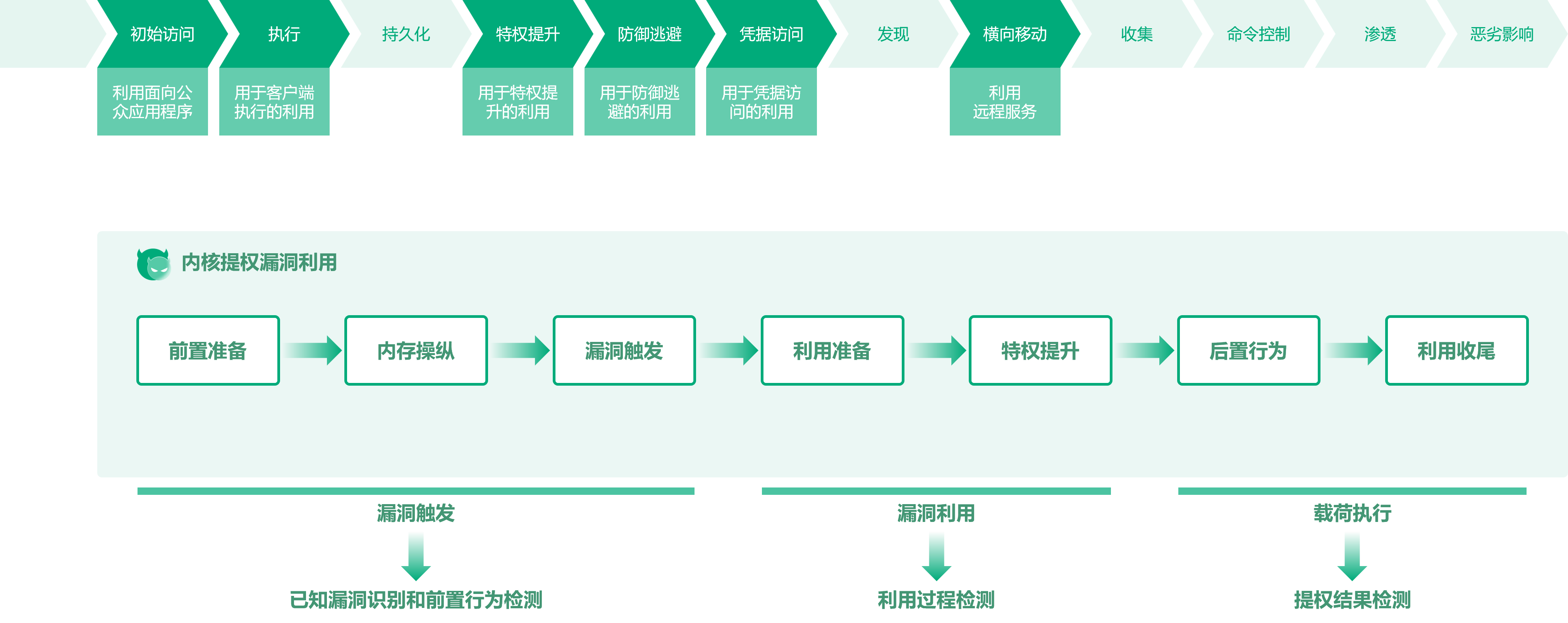
一个典型的内核提权漏洞的利用过程可以分为几个阶段:漏洞触发阶段、利用过程阶段、载荷执行阶段。
漏洞触发阶段包括前置准备、内存操纵、漏洞触发三个部分,为了成功触发漏洞,攻击者往往需要执行大量的准备工作。利用过程阶段包括利用准备和特权提升两个部分,其中利用准备阶段执行从漏洞触发到利用成功之间的准备工作,为了成功完成利用,攻击者需要对系统环境进行构造,比如内存占位、ROP、内核堆风水布局等。载荷执行阶段是利用过程的后置阶段,包括后置行为和利用收尾两个部分,此时攻击者已经达成了利用目标,正在执行后续的载荷行为,必要时还有对应的环境修复等收尾操作。
检测手段可以覆盖漏洞触发、利用过程、载荷执行这三个阶段。就像是在现实世界战争中,反导拦截技术一样,针对弹道导弹发射期间的助推段、中段、末段均可以实施拦截,但中段拦截技术难度最高、拦截效果最好。对应的,在漏洞利用检测手段中,也是在利用过程阶段进行检测的技术难度最高,但也会有更有效和准确的检测结果。
在这里我以 CVE-2017-0263 内核提权漏洞为例,描述此类漏洞的利用过程和对应的检测思路。
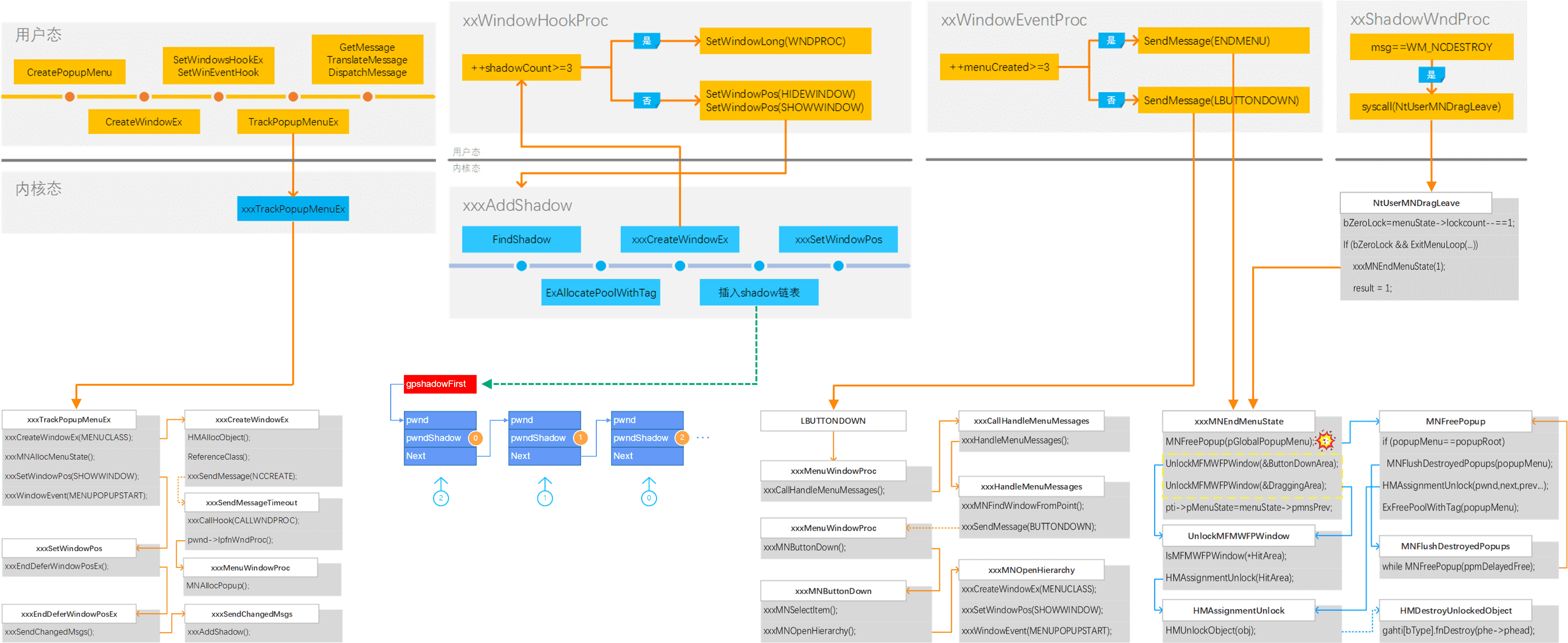
CVE-2017-0263 是 APT28 组织用来攻击影响法国大选所用的 0day 漏洞之一,最早由 ESET 等公司发现并捕获。这个漏洞是位于 Win32k 内核模块中属于窗口管理器子系统的一个 UAF 漏洞。在终止菜单状态的内核函数中,对全局菜单状态对象的一个成员变量指向的全局弹出菜单对象执行释放操作时,没有将这个成员变量置为空值,导致这个成员变量在其指向的内存区域被释放后仍可以被引用,导致在后续的执行流程中存在被释放后重用或重复释放的潜在风险。
攻击者要触发并利用此漏洞,需要通过复杂的流程,通过利用技巧构造具有特殊关联和属性的窗口对象,导致在内核中的特定时机执行流从内核重新回到用户进程上下文,用户进程上下文中的利用代码将有足够的能力改变当前弹出菜单的状态,导致执行流重新执行终止菜单状态的内核函数,对全局弹出菜单对象进行重复释放并执行对应的解析操作,最终通过内核上下文执行攻击者在用户进程上下文构造的利用代码,实现内核提权的目的。这个漏洞的利用过程还有很多细节操作在这里没有提及,感兴趣的读者可以查阅我之前的文章:《从 CVE-2017-0263 漏洞分析到 Windows 菜单管理组件》。
针对此类漏洞,沙箱云已支持覆盖了漏洞触发、利用过程、载荷执行这三个阶段的检测技术,并且能够对漏洞从触发、到利用、到载荷执行,各个阶段的利用行为和状态,进行检出。
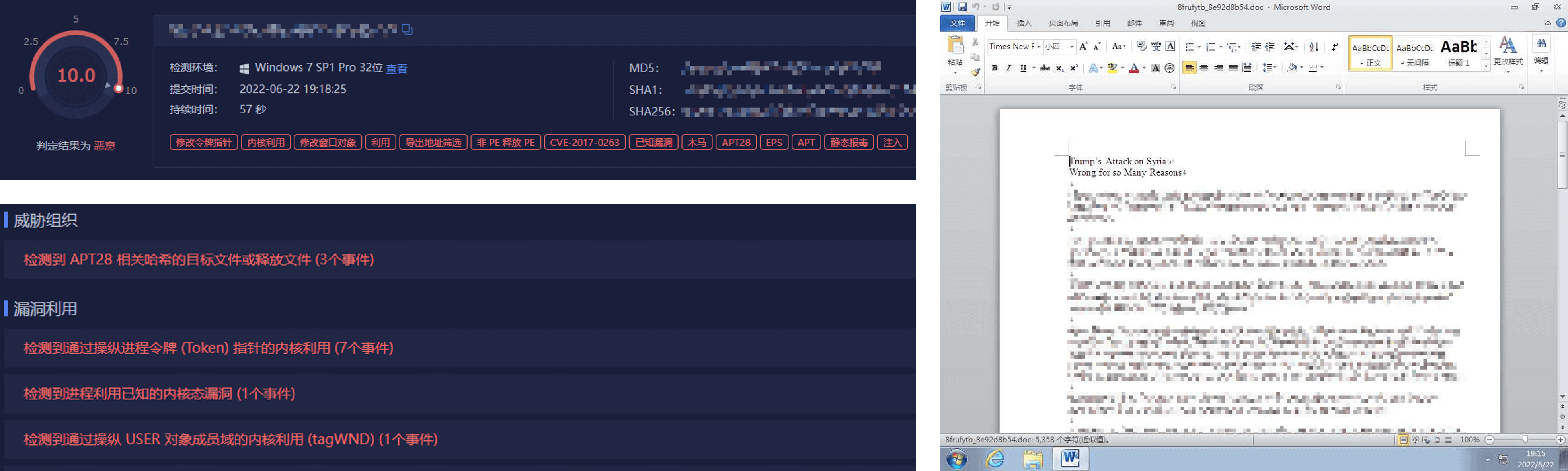
基于机器学习的检测技术实践
在具体的实践中,传统的基于特征和已知技术的检测方案不是万能的,往往也会遇到各种不足和短板。面临使用新型利用、绕过和攻防技术的恶意程序层出不穷的严峻现状,沙箱云借助机器学习技术,应对各种新型恶意程序和攻击,实现针对新型攻击的检测发现。沙箱云研发并集成多种机器学习模型,并在威胁检测过程的各个阶段使用 AI 技术进行检测,为沙箱云在威胁判定能力方面提供更为有效的支撑。

我们使用像 DGA 域名识别模型、网络流量检测模型、动态行为检测模型、文件静态检测模型等机器学习模型作为检测技术的辅助,增强自动化威胁检测的能力。
机器学习模型需要持续完善。我们通过训练、实践、反馈这三个步骤的循环,持续优化我们的 AI 检测能力。
海量样本数据运营
要进行高级威胁的持续自动化发现,离不开海量样本数据作为来源。面对海量的威胁样本数据,必须及时获取有关这些数据的准确信息。如何有效获取、收集和处理这些信息,正在成为威胁应对过程中的主要挑战之一。接下来,我将简单描述一下如何进行海量样本数据的运营,以及做好海量样本数据的运营如何支撑起情报生产和高级威胁发现的任务。
什么是漏斗模型?
为了进行海量样本数据的运营,首先引入一个叫做“漏斗模型”的概念。
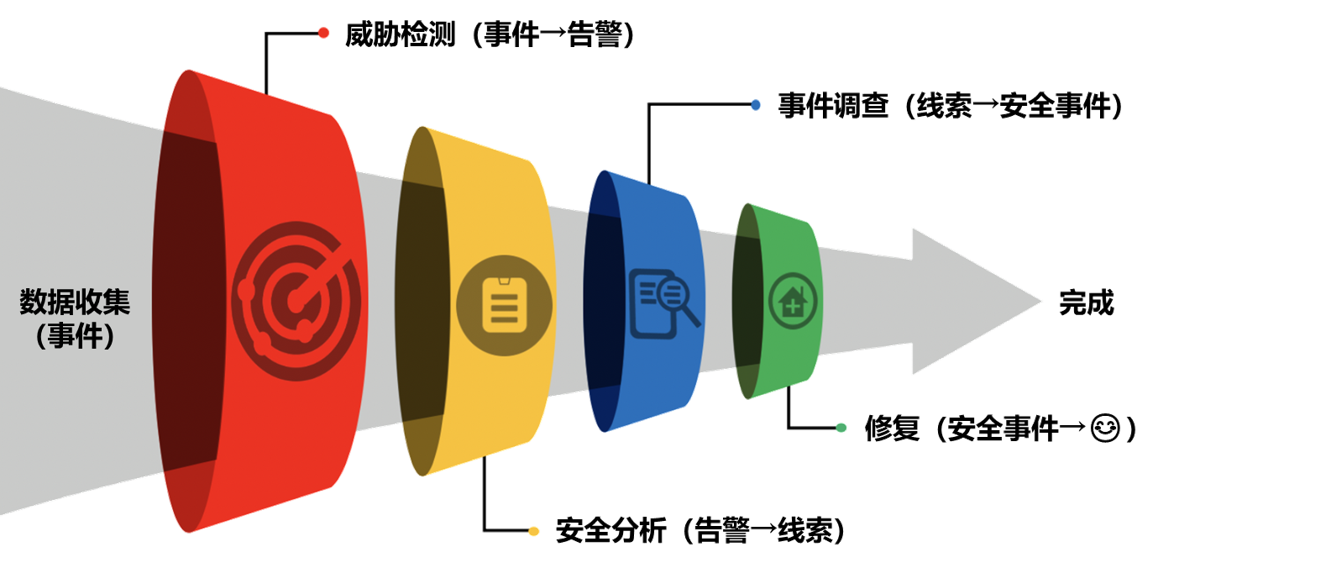
什么是漏斗模型?这个概念是由SpecterOps公司提出,描述检测和响应过程中涉及的阶段,这家公司提出了漏斗模型的概念,用于描述数据收集、威胁检测、安全分析、事件调查、和修复等几个阶段。该模型认为,在威胁检测和响应中,目标是如何高效利用有限的资源来达成目的,因此需要过滤掉无用的信息,把注意力集中的大概率为真的安全事件上。
面向海量样本数据运营的漏斗模型
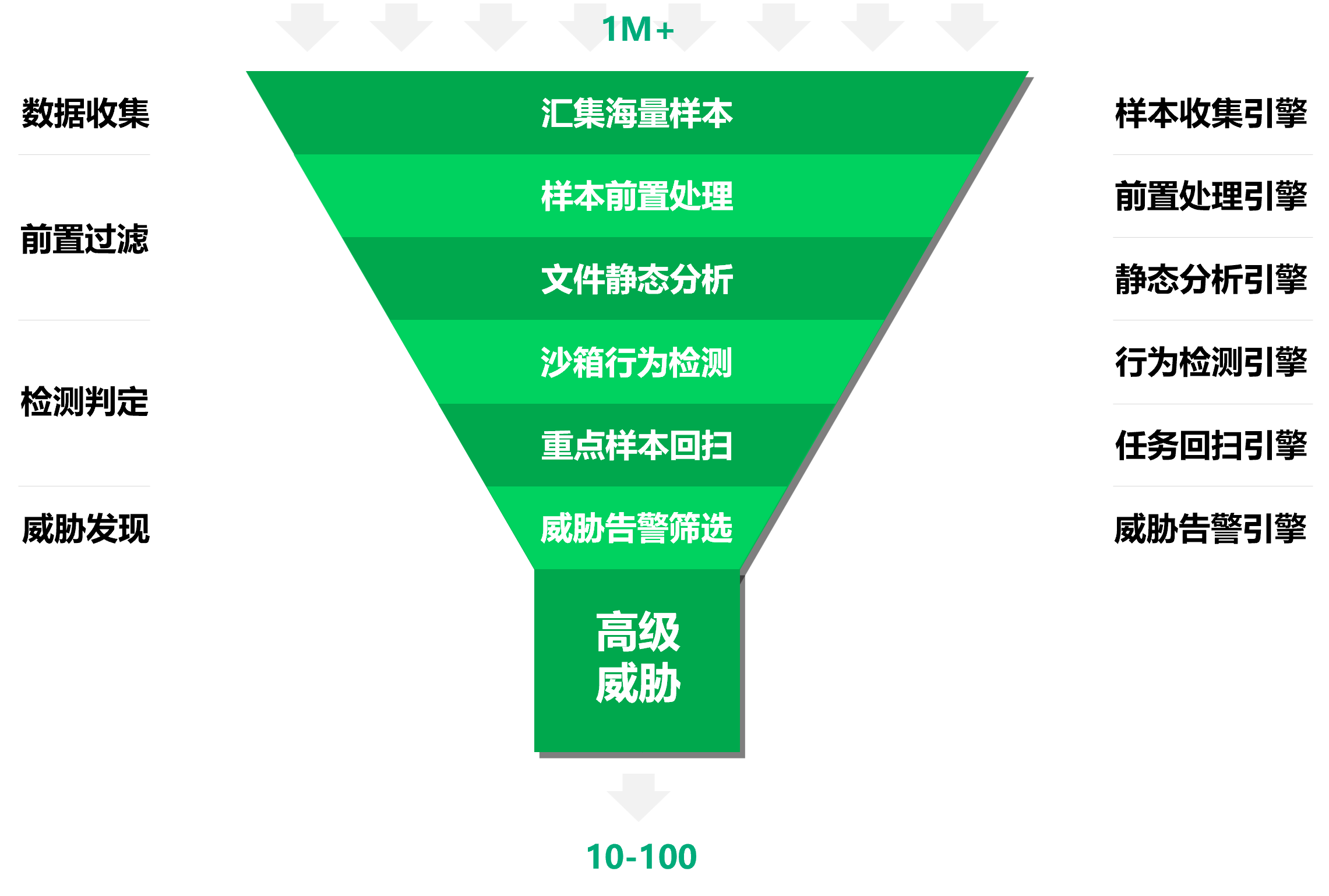
为了适用于针对威胁检测的海量样本数据运营,我们提出了面向海量样本数据运营的漏斗模型。
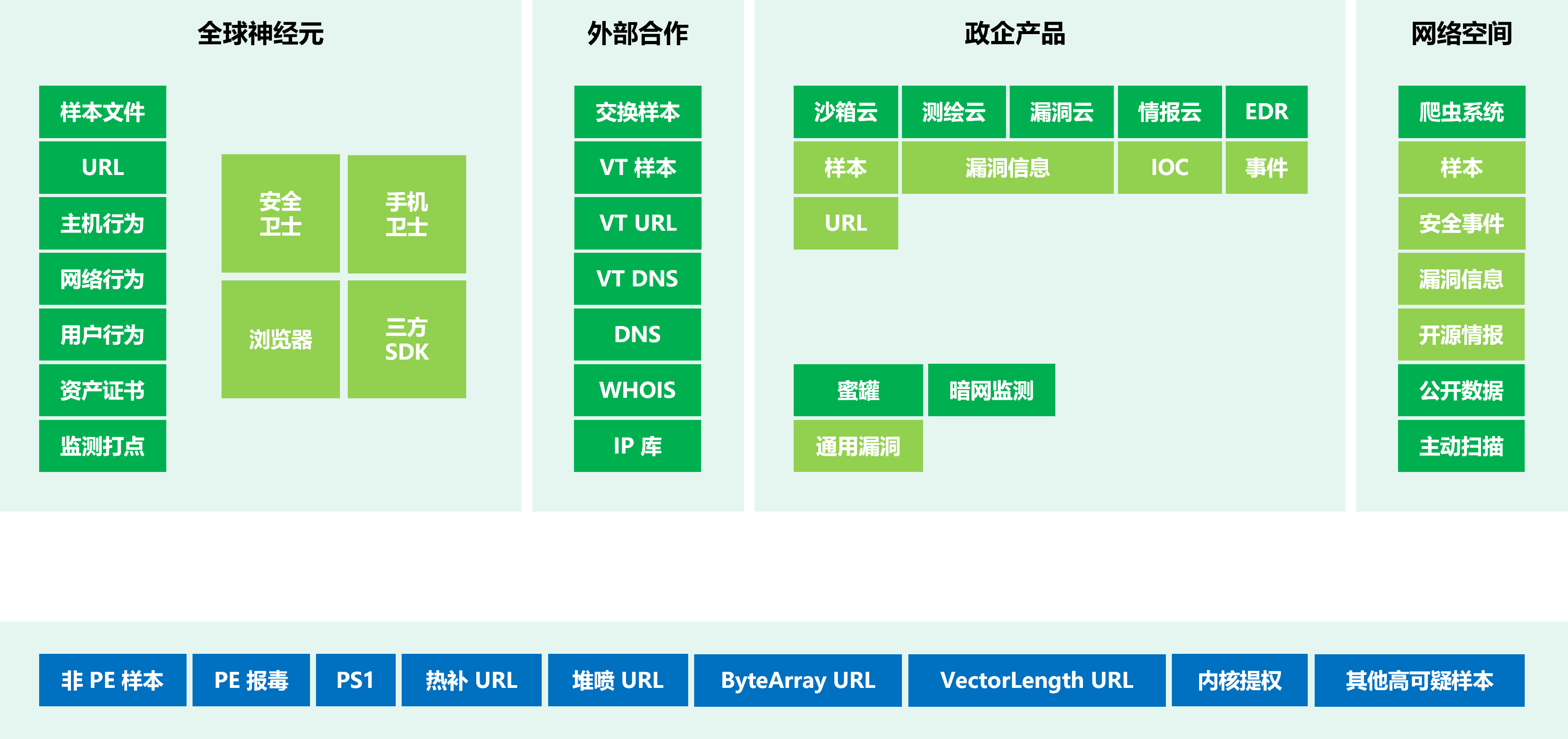
多重样本来源
基于输入的海量样本数据,经过各个检测分析阶段的处理和过滤,最终的目的是发现高级威胁。我们以数据收集、前置过滤、检测判定、威胁发现等几个阶段进行划分,针对输入的每天数百万级的样本数据,通过多层筛选和过滤去除无用数据,最终筛选出真正需要关注的威胁事件和样本数据。
前置过滤处理
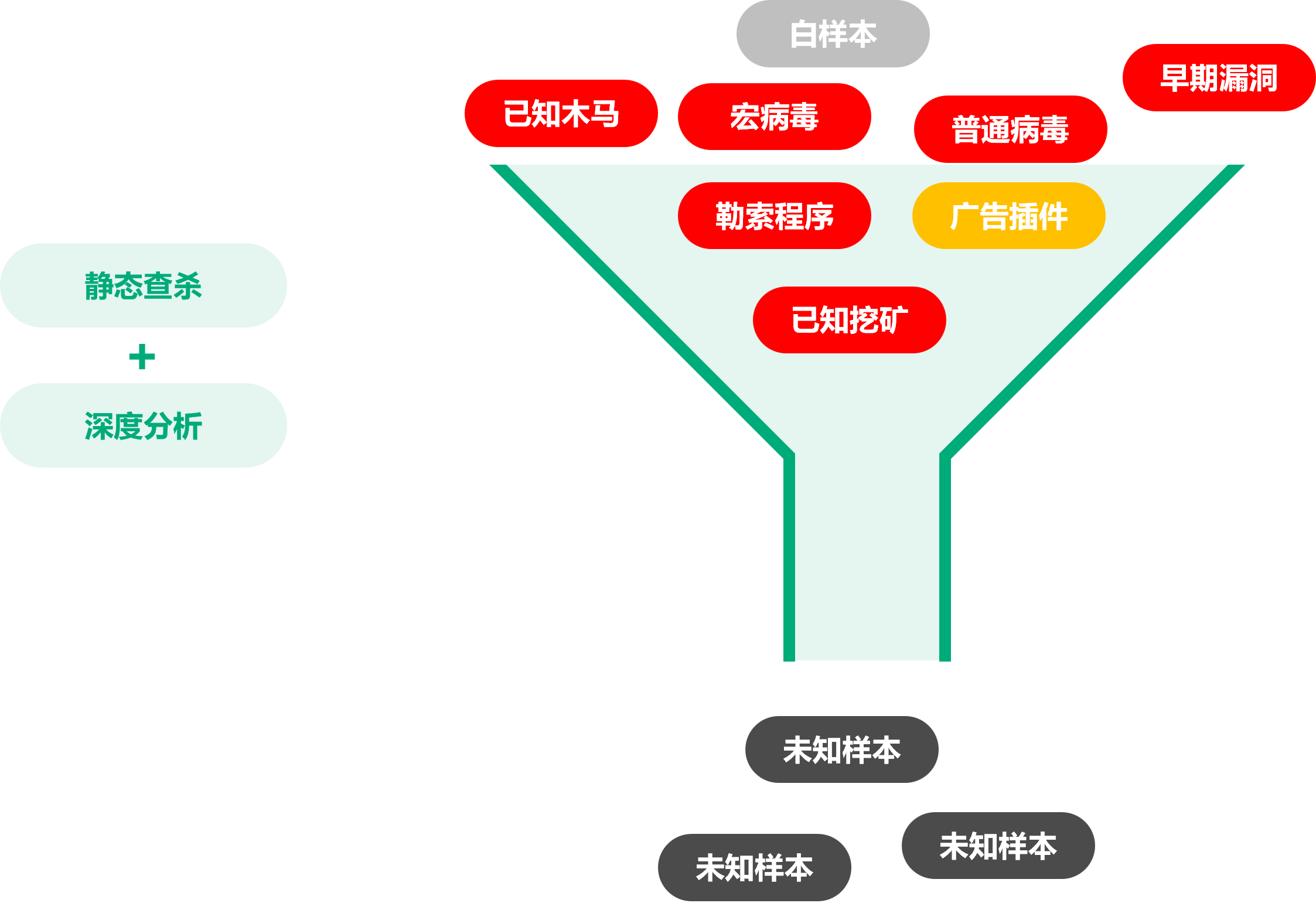
在对汇集筛选出的样本数据进行检测运营之前,需要对其进行前置过滤处理,以使运营任务、在有限的系统资源中高效运行。在前置过滤阶段,我们经过数据标准化、样本数据消重、多引擎查杀、文件内容深度提取解析、和常规威胁过滤等多道手续,清除无效信息,并输出高可疑的未知样本数据。
自动化检测判定策略
通过前置过滤阶段获得的高可疑未知样本数据,接下来会经过自动化检测判定策略进行检测分析。我们对这些样本数据进行分类分组,根据预定策略,将分组的样本数据投递至不同运行环境进行检测。
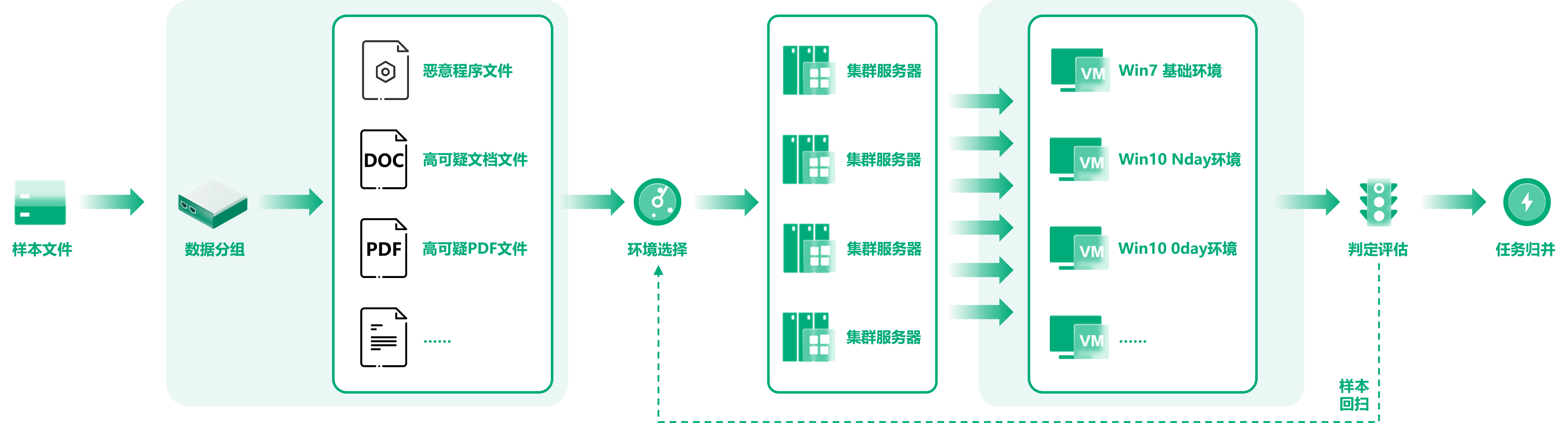
比如,根据 PE 文件的位数和版本将高可疑PE文件投递至对应位数和版本的操作系统、根据文档文件的内容信息选择安装了不同应用程序版本的运行环境。
海量样本数据的自动化检测,需要大规模的服务器集群作为支撑。检测完成之后的采集数据,会用来进行判定评估。我们根据判定评估的结果,决定部分样本数据是否需要进行回归扫描,选择不同版本或补丁的运行环境,进行额外的检测流程。同一个样本的多次检测任务,在最终会进行任务的归并。
情报生产和高级威胁发现
海量样本数据的运营,用于支持情报生产业务和高级威胁发现业务。接下来我将简单描述一下如何基于海量样本数据运营进行情报生产和高级威胁发现。
什么是威胁情报?
要进行威胁情报的生产,首先需要了解什么是威胁情报。
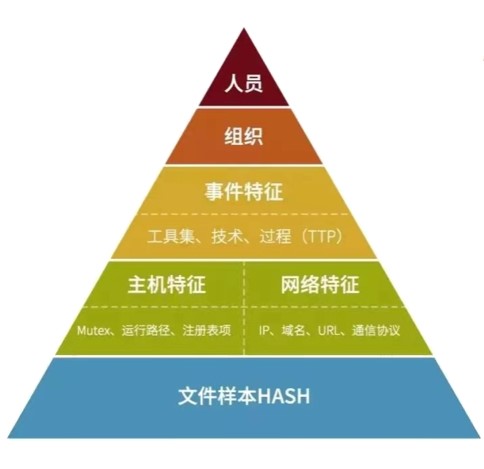
根据 Gartner 和 NCSC 的定义,威胁情报是关于资产所面临已有的、或即将发生的威胁或危害的基于证据的知识,包括上下文、机制、指标、影响和可行建议。威胁情报可以分为 4 类:技术情报、战术情报、操作情报、和战略情报。在这里我们提到的情报生产,主要涉及的是技术情报和战术情报。在有些分类方式中也将这两个类型划为一类。
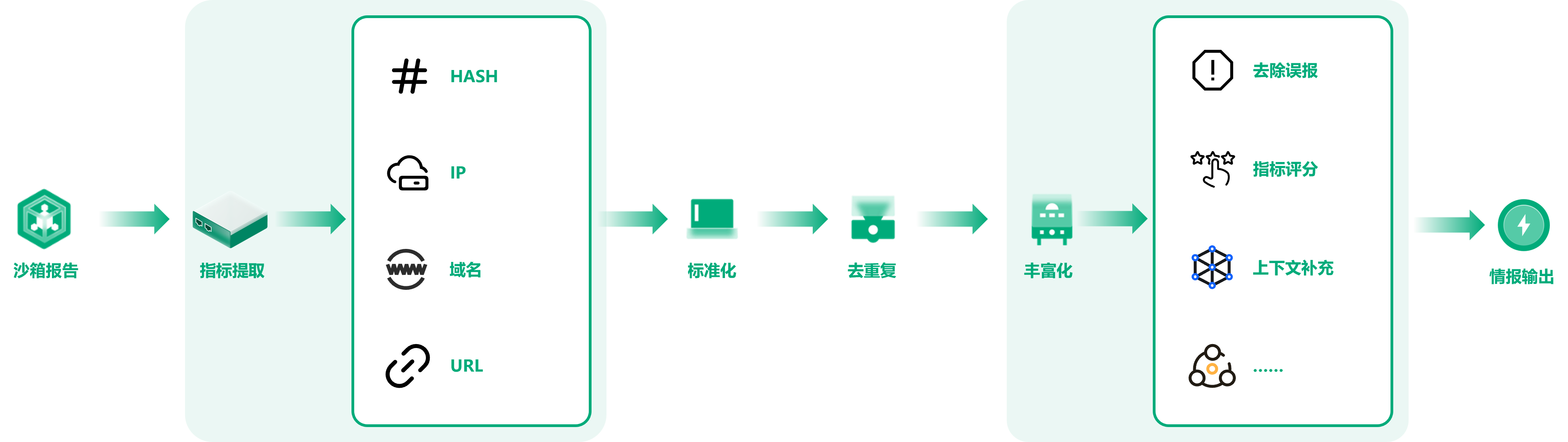
情报生产
在情报生产业务流程中,我们首先从沙箱报告中提取对应的指标,包括代表文件信誉的哈希,和 IP 地址、域名、网址,然后对提取的指标进行标准化处理和去重复处理,使指标数据的各项字段和格式符合情报标准的要求。然后我们对指标数据进行丰富化处理,包括去除误报、指标评分、上下文补充,这些处理是依赖于信誉库和沙箱报告中的其他内容进行的。最后是情报的输出。
什么是高级威胁?
海量样本数据的运营,支撑的另一项主要的业务是高级威胁发现业务。那么什么是高级威胁呢?
行业中针对高级威胁这个概念有很多种不同的定义,但是有一种较为通用的说法是:利用持续且复杂的攻击技术来获得系统访问权,并且有可能造成毁灭性后果的威胁。高级威胁有几个特性,第一是持续使用新型的攻击技术,具有很强的破坏性;第二是通过各种攻防对抗和检测逃避的手段对抗检测和安全设施,具有很强的隐蔽性;第三是通常使用漏洞、甚至使用 0day 进行攻击。
高级威胁发现
在高级威胁发现业务流程中,我们对沙箱报告的内容进行解析,获取其中的动态行为、网络行为、样本分类、样本特征、威胁图谱、威胁指标等数据,并根据判定指标策略和报告内容策略对威胁级别进行评估,使用任务标签对威胁类型进行划分。最终我们基于高级条件的筛选策略,对威胁数据进行最终的筛选,最终得到真正需要关注威胁数据进行告警推送。
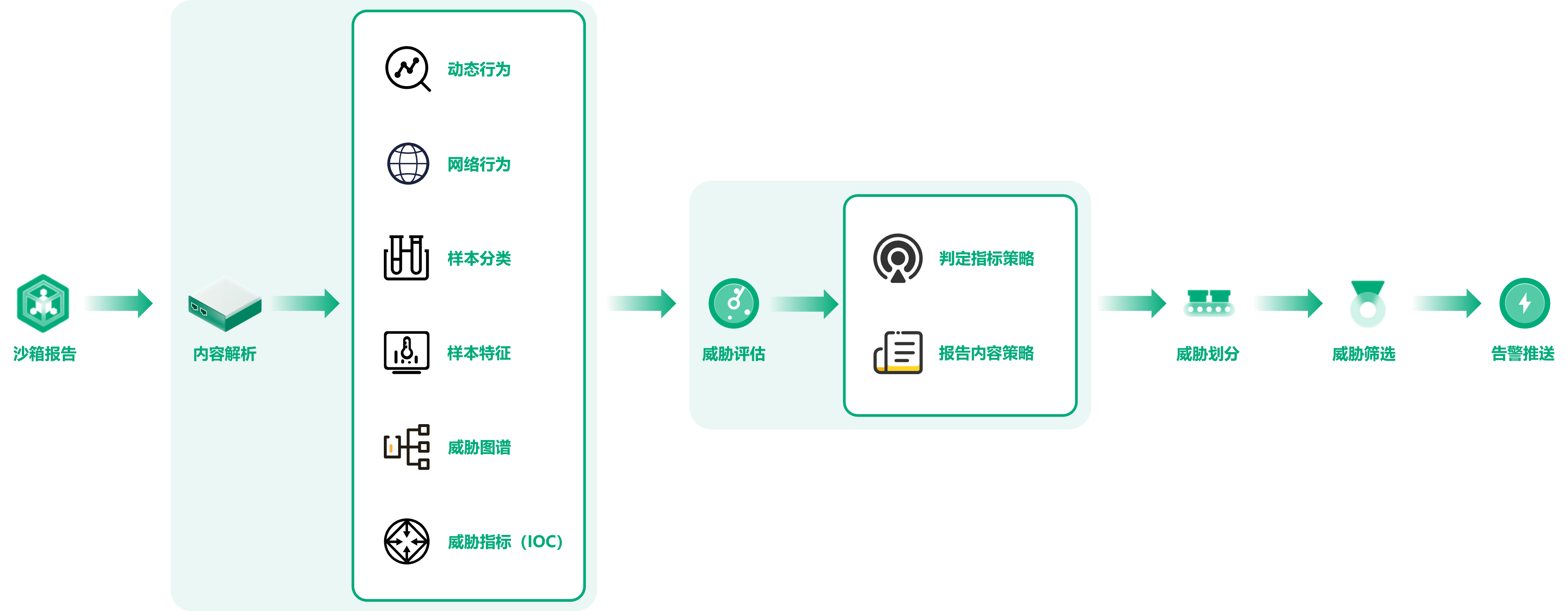
我们将生成的威胁告警数据汇集在我们的大数据中心,以不同的维度和类型对这些威胁告警数据进行存储和关联,并在各个业务场景中接入使用。
高级威胁发现业务不可能是一成不变的流程,前面提到了基于高级条件的筛选策略,我们会通过运行任务、接受告警、检验结果、反馈策略这四个步骤的持续循环,对策略不断进行优化。自动化高级威胁发现流程需要持续的改进,才能使“发现高级威胁”的这个终极目标实现可持续,才能使“看见”更进一步。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=fg5kpi6idrce
- THE END -
刀师傅牛逼!
感谢阅读~~